Some thoughts on logging
clojureHave you ever tried to log from a multi-threaded program? Have you tried to make sense of log output when multiple subsystems were logging to it? Have you tried to do average latency calculations based on that log file?
If you’re reading this blog, I’m guessing you answered yes to a couple of the questions above.
There are multiple problems here: multiple producers (race conditions), out-of-order logs, conflated subsystems in the same logs, etc. You have to put a lot of effort into your log post-processor to make any sense of the data, decorating it with various metadata to make it possible at all.
In this post, I point out a few ways you can use Clojure (both the language and its general ethos) to overcome these problems. The solutions here are primarily tailored to “pipeline systems” where you want to find time-consuming bottlenecks and produce latency reports, etc. For simplicity, this is in-process logging, where all the parts (threads) can share a log resource and tick timer, etc.
TL;DR the complete code snippet.
Agents
First off, the race conditions; if the log is simply a file, or a in-memory data structure, you have to somehow serialize the “emit” calls. Conventional wisdom would have you put the emit call in a critical section, but this is a) ugly b) can introduce deadlocks c) can effect the system under stress. We want to post a log entry using a lock free, asynchronous mechanism, that’s why we have agents in Clojure;
(def log (agent []))
(defn emit
"Emit data to the log"
[data]
(send log #(conj % data)))
(defn emit-timed
"Emit datas to the log, timestamp appended"
[data]
(emit (assoc data :time (System/nanoTime))))
Please note that when emitting with timestamps, we take a snapshot of the time instantly (in the context of the calling thread), not in the agent-thread context later on.
Tree Logging
How do we apply structure to the log data? One idea is to put the log data into a tree instead of a flat vector (or file). Then log entries from different subsystems can be separated (for easier post-processing), and we can express dependancy between log events for latency calculations.
Lets say each log entry is associated with one id and multiple correlation ids. The id is typically an UUID which you assign to a request, operation, instruction that “travels” through multiple parts of your system. The correlation ids can be used a splitting your logs into categories of arbitrary depth, yield possibly more meaningful reports etc.
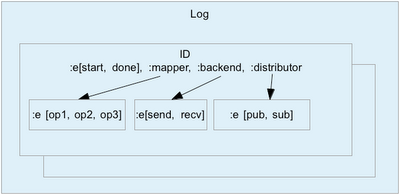
Here’s how such a tree structure can be built using Clojure’s maps and the mighty assoc-in function;
(def log (agent {}))
(defn- add-log [id data time & corr-ids]
(send log #(let [keys (into [id] corr-ids)
log-node (get-in % keys {:entries []})
entries (:entries log-node)]
(assoc-in % keys
(assoc log-node :entries
(conj entries {:time time
:data data}))))))
(defn emit
"Emit data to the log, with a given id and potential corr-ids"
[id data & corr-ids]
(apply add-log id data (System/nanoTime) corr-ids))
The logger handles the timestamping for you, it also gives you functionality such as extracting chronological logs for ids, and timing/latency reports.
(defn get-ids
"Get all ids in log"
[log]
(keys log))
(defn- walk-nodes [node f path]
(when node
(f node path)
(doseq [child-id (filter #(not= % :entries) (keys node))]
(walk-nodes (get node child-id) f (conj path child-id)))))
(defn get-log
"Get all log entries for a given id in chronological oder"
[log id]
(let [evts (atom [])]
(walk-nodes (get log id)
(fn [n _] (swap! evts #(into % (:entries n))))
[id])
(->> evts (sort-by :time) (map :data))))
Ok, this looks like it might perhaps work, but there are some drawbacks; we must keep the tree in memory for processing, which can be hard for huge logs, also serialisation to disk is trickier (but no really if you have a reader). We’re also forcing a structure upon the log data, that feels awkward. Supplying the id, and corr-ids is not as clean as it could be.
Metadata
Let’s get back to a simple flat log and more metadata in the events. We use the metadata to express the categories and other dependancies between the events that we used the tree for in the previous example. In a sense, we are still using a tree (or maybe even graph) data structure, but the branching is described with metadata in sequence of events. Using the emit function describes under the “Agents” paragraph above, here and example of some “connected” log events;
(let [id (java.util.UUID/randomUUID)]
(emit-timed {:id id :op :add})
(emit-timed {:id id :cat :backend :op :send})
(emit-timed {:id id :cat :backend :op :ack :parent-op :send})
(emit-timed {:id id :cat :backend :op :sub :parent-op :send})
(emit-timed {:id id :cat :distribution :op :contribute})
(emit-timed {:id id :cat :distribution :op :chain-contribute})
(emit-timed {:id id :cat :distribution :op :chain-event :parent-op :contribute})
(emit-timed {:id id :op :done :parent-op :add})))
The helper functions also becomes much cleaner this way;
(defn get-ids
"Return a set of ids seen in the log"
[log]
(->> log
(map :id)
set))
(defn get-log
"Get chronological logs for a given id"
[log id]
(->> log
(filter #(= (:id %) id))
(sort-by :time)))
Please note that these functions take a (de-referenced) log rather than using @log directly. This helps testing, but is also very important for more complicated (looping) functions which should work on a stable snapshot of the log events.
Conclusion
The flat log file with simple events described as Clojure maps worked out really well, and it’s certainly more idiomatic. The log is easier to serialize; we only need parts of it in memory for meaningful analysis, and we can treat it as a continuous stream. The analysis functions that we write can leverage the power of Clojure’s library directly and compose beautifully. Also, we are not forcing any structure (or schema) on the log events (more than any analysis functions expect), which makes it very flexible and future-proof. The only price we are paying is additional (redundant) metadata that can be more cheaply expressed in a tree data structure.
Here’s a complete listing of an event logger using metadata, with statistical reporting.