Flexible multi consumer/producer pipelines
clojureTL;DR: Pipejine - a lightweight Clojure library for multi-threaded producer/consumer pipelines supporting arbitrary DAG topologies.
Recently, a colleague and I faced a problem where we needed to optimize the total running time of a complicated calculation. This calculation involved several asynchronous steps getting data from other systems (like Elasticsearch and other home-grown services), along with some number crunching and tallying up the results at the end. Here is a simplified example of the system:
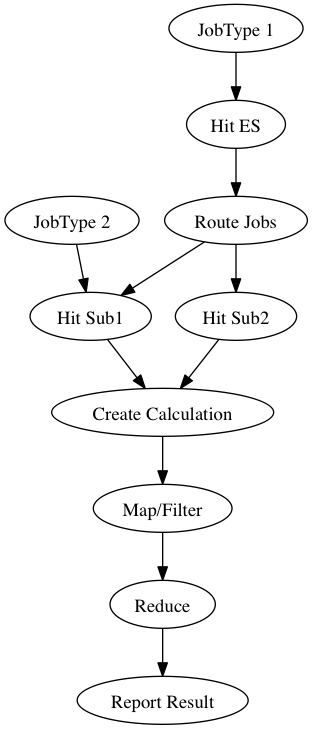
Some work items could come “out of order,” and some had to hit different systems before “coming back” and being part of the remaining calculation.
To improve performance, the communication with some of these services needed to be batched. The total amount of data flowing through the steps far exceeded the heap size of a single VM, so we had to carefully partition the data and keep only parts of it in memory at any time. Different steps required different amounts of resources (memory/threads, etc.) - so we needed to balance the entire system.
The different steps had different failure characteristics, and it was important that the entire calculation didn’t lock up when a part behaved badly, and try to recover from a bad situation as well as possible. Since the whole calculation is highly multi-threaded, we had to have a way of determining when the entire calculation was done so we could pass on the final result. This “done signal” also had to be consistent in error situations.
Because of the complexity of the many steps, it was important to track the status of the whole system to identify potential problems and bottlenecks. Finally, we wanted many different calculations to run in parallel (independent of each other) and to be able to cancel individual ones within reasonable time frames.
That’s quite a lot of requirements. How can you describe something like this (in Clojure) without pulling your hair out and going mad? Well, this looks like a pipeline problem, doesn’t it? There are a few Hadoop-like/Storm-like solutions out there, but all this had to run inside a single VM, and the problem wasn’t really “big data” enough to justify Hadoop – we didn’t want to use a thermonuclear bomb to open a matchbox. We also wanted our pipeline to handle our quirky requirements (like batching) transparently from the producer/consumer functions.
I’ve put what we came up with on GitHub, and I’m happy to say that it managed to solve the problems described above very neatly while remaining small and nimble. It’s basically some helper functions over Java’s powerful concurrent queues. And as it turns out, by using these primitives we managed to write a simple and flexible solution.
So if you find yourself with a similar “not big enough for Hadoop” problem, please feel free to give Pipejine a spin!